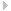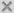A scale-out file system consists of a set of on-premises file systems and set of cloud tier(s) all exposed in a single name space. One on-premises file system stores the metadata (including the attributes) and all the other file systems store the data. Data is distributed among the file systems using a consistent hashing algorithm. This separation of metadata and data allows the scale-out file system to scale linearly.
Unlike a standard file system, a scale-out file system is Active/Passive, which means that the file system can be online on only one node of the cluster at a time. A scale-out file system is always active on the node where its virtual IP address is online. A virtual IP address is associated with a scale-out file system when the file system is created.
Veritas Access supports access to scale-out file systems using NFS-Ganesha and S3. NFS shares that are created on scale-out file systems must be mounted on the NFS clients using the virtual IP address that is associated with the scale-out file system, similarly S3 buckets created on a scale-out file system must be accessed using the same virtual IP address.
S3 buckets created on a scale-out file system must be accessed using virtual-hosted-style URL (rather than the path-style URL) and the S3 client's DNS must be updated to this virtual IP address for the corresponding virtual-hosted-style URL. If a bucket "bucket1" is created by the S3 client, then its virtual-hosted-style URL would be "bucket1.s3.cluster_name:8143," where the cluster_name is the Veritas Access cluster name and 8143 is the port on which the Veritas Access S3 server is running.
Scale-out file system specifications:
Twenty percent of a scale-out file system's size is devoted to the metadata file system.
The maximum size of a metadata file system is 10 TB.
The minimum size of a scale-out file system is 10 GB.
The maximum size of a scale-out file system is 3 PB.
To create a scale-out file system above 522 TB, you need to provide the file system size in multiples of 128 GB.
You can grow a scale-out file system up to 3 PB.
To create or grow a scale-out file system above 522 TB, you need to provide the file system size in multiples of 128 GB.
Growing a scale-out file system beyond 522 TB creates additional data file systems (based on the grow size), and data movement is triggered from the old file systems to the newly added file systems, so that data is distributed evenly among all the data file systems.
You can shrink the scale-out file system only if its size is less than 522 TB.
Access the data present in a scale-out file system using NFS (both v3 and v4) and S3 (supports both AWS signature version 2 and version 4).
Ability to tier infrequently accessed data to the cloud using the cloud as a tier feature:
There can be only one on-premises tier.
There can be up to eight cloud tiers per a scale-out file system.
You can move data between cloud tiers, for example, moving data from Azure to Glacier.
Configure policies to move data from or to on-premises or cloud tiers.
Policies can be configured based on the access time, modification time, or pattern.
Azure has a limitation of 500 TB per storage account. Azure users can have 200 storage accounts per subscription. A Scale-out file system supports adding multiple Azure storage accounts in a single tier. Effectively, you can attach 100 PB of Azure storage to a single tier. When multiple storage accounts are used, Veritas Access selects one of the storage accounts to store data in a round-robin manner.
New data file systems are created when you grow the scale-out file system beyond 522 TB. The pool on which the scale-out file system is created is used to create these new file systems. There is also data movement to these new file systems so that data is distributed evenly among all the file systems (on-premises).
The following types of clouds can be added as storage tiers for a scale-out file system:
Amazon S3
Amazon Glacier
Amazon GovCloud (US)
Azure
Alibaba
Google cloud
IBM Cloud Object Storage
Veritas Access S3 and any S3-compatible storage provider
The data is always written to the on-premises storage tier and then data can be moved to the cloud using a tiering mechanism. File metadata including any attributes set on the file resides on-premises even though the file is moved to the cloud. This cloud as a tier feature is best used for moving infrequently accessed data to the cloud.
Amazon Glacier is an offline cloud tier, which means that data moved to Amazon Glacier cannot be accessed immediately. An EIO error is returned if you try to read, write, or truncate the files moved to the Amazon Glacier tier. If you want to read or modify the data, move the data to on-premises using tier move or using policies. The data is available after some time based on the Amazon Glacier retrieval option you selected.
When Amazon S3, AWS GovCloud(US), Azure, Google cloud, Alibaba, IBM Cloud Object Storage, Veritas Access S3 and any S3-compatible storage provider is used as the cloud tier, the data present on these clouds can be accessed any time (unlike in Amazon Glacier). An EIO error is returned if you try to write, or truncate the files moved to these clouds. If you want to modify the data, move the data to on-premises using tier move or using policies.
See the Veritas Access Cloud Storage Tiering Solutions Guide for more information.
You cannot use the CIFS protocol with a scale-out file system.